Application Note: Shared Memory#
Using the Shared Memory on imaFlex and marathon Frame Grabbers#
Each of the operators which use memory are allocated to one physical memory only on the frame grabber. On the imaFlex and microEnable 5 marathon frame grabbers, the concept is different. On these frame grabbers, you can use a much faster DDR4 (on imaFlex) or DDR3 (on marathon) memory. However, this is only one single physical memory so all VisualApplets operators which use the memory share the bandwidth.
The memory configuration of a frame grabber can best be determined from the VisualApplets Device Resources Documentation. In this documentation you find information, which is relevant for the usage of a DRAM element within a VisualApplets design: RAM size, RAM data width and bandwidth per RAM (for all platforms except the marathon series) and RAM bandwidth total (shared) for the marathon series.
信息
The bandwidth values given in the VisualApplets Device Resources Documentation are theoretical, maximum values. In practical use, the efficiency may be reduced.
This document guides you to efficiently use the memory for a specific platform by using the information of RAM size and RAM data width. It also helps you to calculate the resulting bandwidth per RAM for the marathon series.
Efficient Usage of the DRAM#
In the VisualApplets Device Resources Documentation, you find information about the RAM size of a specific platform:
- For the imaFlex CXP-12 Quad: 3 x 512 MiB DDR4
- For the imaFlex CXP-12 Penta: 5 x 512 MiB DDR4
- For the marathon series and Lightbridge: 4 x 512 MiB DDR3
These values give information about the total RAM size (e.g. for the marathon series: 4 x 512 MiB = 2 GiB (2^31 Byte)) and which partition one VisualApplets operator can use at maximum (for the marathon series: 512 MiB).
You can only use this maximum RAM size per operator efficiently, if you use the information of the full RAM data width (see also the VisualApplets Device Resources Documentation):
- For the imaFlex CXP-12 Quad, the RAM data width is 384 bit
- For the imaFlex CXP-12 Penta, the RAM data width is 640 bit
- For the marathon VCX-QP and VF2, the RAM data width is 512 bit
- For the marathon VCL, VCLx, and Lightbridge, the RAM data width is 256 bit
The RAM data width is the bit width multiplied with the parallelism and the kernel elements of a link connected with a DRAM operator in a VisualApplets design.
Example Usage of DRAM#
The example uses a simple VisualApplets design for the marathon VCL platform as shown in the following figure.
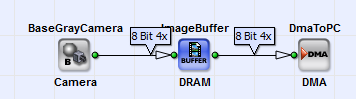
The example uses a parallelism of 4 and a bit width of 8 bit. Thus, the example only uses a RAM data width of 4 x 8 = 32 bit. However, to be fully efficient, the bandwidth needs to be 256 bit. Therefore, you must increase the parallelism to 32 as shown in the next figure.

Now, this design ensures that you can use the DRAM efficiently. In general, it's always best to fully use the available RAM data width. However, sometimes, this is't possible, because you'll need more resources, you' re data format isn't divisible by 256 or the operator's parameter will not allow the full range anymore. Therefore, you need to know if you can use a lower parallelism as well. For this you'll need to understand the memory bandwidth which is explained in the following section.
Memory Bandwidth#
You can find platform-specific information about the maximum memory bandwidth for one DRAM element in the VisualApplets Device Resources Documentation. As you need to consider reading and writing from RAM, the maximum bandwidth is divided by 2 for the calculation of the resulting bandwidth :

You only achieve this value of the resulting bandwidth if you use the full RAM data width (see section Efficient Usage of the DRAM). Therefore, you need to take the ratio RAM data width used/ full RAM data width into account for the calculation of the resulting bandwidth:

According to this formula, you can calculate the necessary RAM data width:
bit width * parallelism * kernel elements of a link connected to a RAM element used in the design to achieve a specific resulting bandwidth. This means you can also calculate the minimum required parallelism of the link connected to a RAM element, if you have bit width and kernel elements defined.
Example Memory Bandwidth Calculation#
You can calculate the resulting bandwidth for the design examples in section Memory Bandwidth. For the design example displayed in figure 1 with a RAM data width of 32 bit, the resulting bandwidth is:

For the design example displayed in figure 2 with a RAM data width of 256 bit, the resulting bandwidth is:

Shared Memory#
The bandwidth calculation formula in section Memory Bandwidth is true for all frame grabber platforms, when only a single DRAM operator exists. It is also true for the bandwidth calculation of each DRAM element in an applet for all platforms except the marathon series. If you use more than one operator, the total memory bandwidth is shared for the marathon series. The resulting bandwidth for one DRAM element is then calculated according to:

Example Shared Memory#
The following example for the marathon VCL platform shows two cameras, two DRAM elements (with RAM data width 32 bit) and two DMAs as shown in the image below:
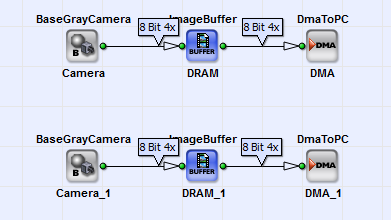
The resulting bandwidth is:

In comparison to the resulting bandwidth calculated in section Memory Bandwidth for a RAM data width of 32 bit but only one DRAM element in the design, the resulting bandwidth with two DRAM elements is half the value as before. To achieve the same bandwidth with two DRAM elements as with one DRAM element, you need to double the RAM data width (= 64 bit).
Operator Configuration#
The operator configuration automatically adapts to the available RAM data width of a given frame grabber hardware. Most operators therefore allow the RAM data width given in the VisualApplets Device Resources Documentation. Some operators only allow a parallelism of one. To overcome the link bit width limitation of 64 bits, some of these operators accept kernels to use an efficient RAM data width as explained in sections Efficient Usage of the DRAM and Memory Bandwidth. There are DRAM operators exceptions, which require special configuration for efficient usage. Details for the best configuration of the operator are available in the operator CoefficientBuffer documentation.